
大家好。
我们现在做数据分析的时候,不可避免地会与文本数据打交道,今天跟大家分享在数据分析中,如何挖掘出相似的文本。
本文从提出问题,到解决问题,再到算法原理三个方面来介绍。
1. 提出问题
假设在一个电商APP里,我们想要找出某款商品评价里,关于“ 快递很差 ” 的评论,该怎么做?
如果只用字符串匹配的方式,你可能会遍历所有的评论,判断每条评论里是否包含“ 快递很差 ”字符串。
但这种做法对下面几条评论就失效了
- 快递真差劲
- 快递一点不好
- 物流真差
所以,单纯的字符串匹配会漏掉很多评论。
2. 解决问题
要解决上面的问题,需要借助 潜在语义索引(Latent Semantic Indexing, 以下简称LSI) 算法。
LSI 算法可以挖掘相似文本,因此,通过 LSI 算法可以找到与“ 快递很差 ”相似的评论。
下面我们以之前一篇文章《 挖掘张同学视频评论主题 》为例,实践 LSI 算法。
2.1 构建 LSI 模型
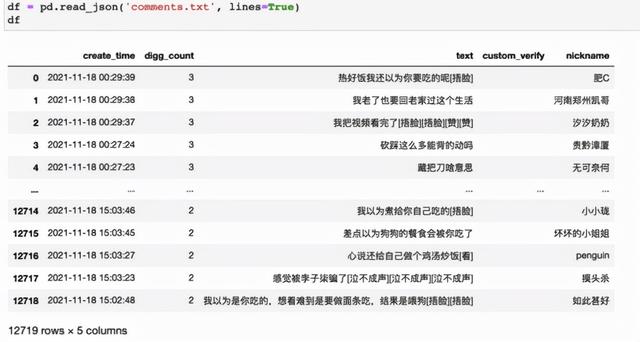

张同学视频评论
上篇文章抓取了张同学抖音视频 1.2w 条评论,对应上图 text 列。
首先,对评论分词,并去掉停用词。
origin_docs = df['text'].values
documents = [jieba.lcut(doc) for doc in origin_docs]
texts = [[word for word in doc if word not in filter_wrods] for doc in documents]

texts变量
然后,用 gensim 构建评论词典,并统计每条评论中每个词出现的次数( 词频 )。
from gensim import corpora, models, similarities
# 构建词典,给每个词编号
dictionary = corpora.Dictionary(texts)
# 每条评论里每个词的出现频次
corpus = [dictionary.doc2bow(text) for text in texts]

corpus变量
dictionary 将 texts 变量中的文本变成了数字编号。如: 热好 的编号为 0, 饭 的编号为 1。
doc2bow() 中的 bow 是 Bag-of-Words 的缩写,代表 词袋模型 ,该模型用来统计评论中的词频。
corpus 变量与 texts 变量相对应。 corpus[0] 中的第一个元组 (0, 1) 代表第一条评论中 热好 一词的出现的次数是1,第二个元组 (1, 1) 代表 饭 出现的次数是1。
接着,构建 LSI 模型
lsi = models.LsiModel(
corpus,
id2word=dictionary,
power_iters=100,
num_topics=10
)
num_topics 是评论的主题数,上篇文章我们挖掘出来8个主题比较好, 这里我们设置的主题数是10个,稍微大一些对后面挖掘相似文本更好。
最后,构建每条评论 向量 的索引,方便后面查询。
# lsi[corpus] 是所有评论对应的向量
index = similarities.MatrixSimilarity(lsi[corpus])
2.2 查询相似文本
张同学的视频评论中,很多人都对“喂狗”镜头印象深刻。
下面我们来查询与“ 以为自己吃,结果喂狗 ”相似的评论。
query = '以为自己吃,结果喂狗'
# 词袋模型,统计词频
vec_bow = dictionary.doc2bow(jieba.lcut(query))
# 计算 query 对应的向量
vec_lsi = lsi[vec_bow]
# 计算每条评论与query的相似度
sims = index[vec_lsi]
经过 LSI 处理后,每条评论都可以用 向量 表示,同样的, query 也可以用 向量 表示。
所以, index[vec_lsi] 其实是计算 向量 之间的相似度,这里用的方法是 余弦相似度 。结果越靠近1说明 query 与该评论越相似。
下面按照相似度倒排,输出与 query 相似的评论。
# 输出(原始文档,相似度)二元组
result = [(origin_docs[i[0]],i[1]) for i in enumerate(sims)]
# 按照相似度逆序排序
sorted(result ,key=lambda x: -x[1])
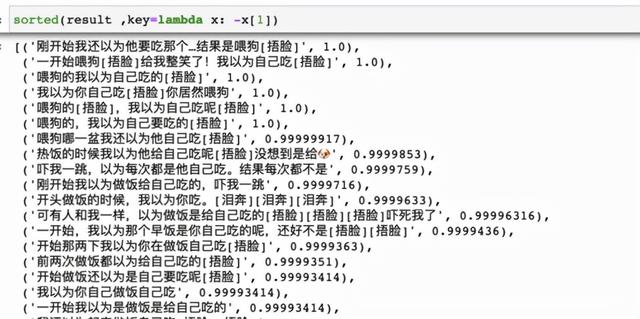
相似文本
可以看到,效果还是不错的,能够挖掘出很多相似的文本。
3. LSI 算法原理
LSI 与我们之前讲的 LDA 类似,都能用来计算每篇文本的主题。
LSI 是基于 奇异值分解 (SVD)的方法来得到文本的主题的。SVD 的近似公式为:
其中,m代表所有评论中词的数量,n代表评论的条数,k代表分解后得到的主题数。
矩阵对应n篇评论,每篇评论下有m个词。
矩阵对应k个主题,每个主题下,m个词的概率分布。
矩阵转置后是 n*k 的矩阵,对应 n 篇文档,每篇文档下,k 个主题的概率分布。
因此,中每行其实就是每条评论的 向量 ,该矩阵对应到上述代码中,是 lsi[corpus] 。
上面我们提到用 余弦相似度 计算向量相似度。在高中数学中,两个向量的余弦相似度其实就是两个向量的夹角
- 夹角0度时,两向量重合(相等),相似度为1
- 夹角90度时,两向量垂直(不相关),相似度为0
- 夹角180度时,两向量反向,相似度为-1
到这里,基于 LSI 的相似文本挖掘就介绍完了。经过本篇的学习,你可以发现 LSI 不仅可以挖掘相似文本,甚至还可以做文本推荐、搜索引擎之类的事。
当然它也有缺点,有兴趣的朋友可以继续深入研究。
如若转载,请注明出处:https://www.summeng.com/51761.html
相关推荐
-
拼多多自动确认收货时间是几天,拼多多自动确认收货时间是几天内?
随着电子商务的兴起,越来越多的人开始在网上购物,而拼多多作为国内最大的社交电商平台之一,深受消费者喜爱。对于拼多多的自动确认收货时间,很多人存在疑问,下面我们就来详细了解一下。 拼…
-
投资亚朵酒店要多少钱(投资亚朵100间客房的酒店花费)
日前,昆明滇池度假区举行招商引资签约仪式,云南璟丽酒店管理有限公司投资采莲湾亚朵酒店项目正式入驻。 亚朵酒店签约 亚朵酒店品牌排名全国前十,在昆明已经有10家,包括南屏街、呈贡大学…
-
怎样在淘宝网上开店卖东西呢,怎样在淘宝开网店,到网上卖商品?
如何在淘宝网上开店卖东西? 如今,随着互联网的快速发展,越来越多的人选择在淘宝网上开店卖东西。淘宝作为一家知名的电商平台,拥有庞大的用户群体和强大的销售流量,给个人创业者提供了极佳…
-
淘宝试用兼职,商品试用兼职?
近期,一种新型诈骗浮出水面。有人在社交平台发布兼职“试衣员”广告,称只需寄拍几张买家秀,就可以轻松赚钱,时间自由月入过万,吸引了不少兼职者加入。 然而,对外声称的“试衣员”兼职实则…
-
淘宝淘金币在哪里看(淘宝淘金币抵扣的钱扣商家的吗)
随着TBC怀旧服进入尾声,游戏内一些以骗金币为生的角色也更加的肆无忌惮,一时间越来越多的玩家抱怨自己被骗了金币,并且联系GM之后也无法得到解决,下面胖哥就和大家聊一聊游戏内常见的十…
-
苹果手机微信视频号怎么制作视频,手机如何制作视频号视频教程?
近期有很多小伙伴私信小蚁问:小蚁小蚁,视频号怎么做呀?有没有什么领域适合新手做的呢等等。视频号内容以图片和视频为主,是一个全新的内容记录与创作平台,从推出到至今一年多的时间,对于创…
-
销售冠军领奖感言,最佳销售获奖感言?
余航的笑容很能感染人。位于淮海中路的理想门店每天人来人往,从不缺客流,进店的每一位客户都容易被有着圆圆的笑脸的余航吸引。 余航似乎天生就合适做销售。数据是直观的体现,作为理想汽车的…
-
成年人快手,成年快手极速版下载安装最新版?
随着快手短视频的流行,成年人们也已经加入到了快手的大家庭中。为了更好地适应成年人的需求,快手推出了成年快手极速版。在本文中,我们将为大家介绍如何下载安装成年快手极速版最新版。 一、…
-
“95后”威海小伙让家乡特产搭上电商发展“快车”
获评“山东省电子商务示范基地”、直播电商和供应链企业交流培训活动风生水起、樱桃节期间大大小小的网络直播火爆……近来,威海市文登区从事电商的团队越来越多。电商发展的背后,有一群先…
-
怎么查看自己是不是淘宝黑号,微查宝?
随着淘宝越来越普及,购物成为人们日常生活中必不可少的一部分。然而,随之而来的就是淘宝黑号的出现,如果你是卖家,那么黑号对你的生意会产生不可避免的负面影响。但是,如何知道自己是否成了…